Regular Expressions, commonly known as Regex or Regexp, are powerful tools for pattern matching and text manipulation. They have a rich history and find applications across various fields. In this tutorial, we'll explore the history, categories, grammar, and practical applications of Regular Expressions.正则表达式历史
1950年:最初由数学学家斯蒂芬科尔·克莱恩正式确定了正则表达的概念。 他使用正则表达方式来描述正式语言的语法。
1960年代:Unix的创建者Ken Thompson在QED文本编辑器中实现了正则表达式。 这标志着正则表达式被引入计算世界。
1980年:Henry Spencer开发了第一个正则表达式图书馆之一,广泛用于Unix系统。
1990年:Perl是一种受欢迎的编程语言,集成正则表达式作为一个核心特点,使更多的受众能够看到。
2000:正则表达式支持扩展到许多编程语言,包括Python、JavaScript和Ruby。
正则表达式历史
元素
字母字符:未列为金属字符的任何字符都匹配自身(例如,“a”匹配“a”)。
元字符:带有保留含义的特殊字符(例如“.”匹配任何字符)。
字符类:定义字符集(如:'[aeiou]匹配任何vowel)。
数量:表示一个字符或组应该重复的次数(例如“*”匹配零或更多次)。
锚:在文本中指定位置(例如,“^”匹配线的开头)。
群组和替换:使用圆括号来分组表达式和“|”来表示替代品(如:'(cat|dog)’匹配“cat”或“dog”)。
要全面了解正则表达式和操作,您可以参考关于正则表达式的维基百科页面。
常见正则表达式操作
布尔值”或” (|):分隔替代。 例如,gray|grey可以匹配”gray”或”grey”。
分组(()):将一系列模式元素分组到单个元素。 允许使用变量(如,$1,$2)引用匹配的模式。
量化(?, *, +, {M}, {M,}, {,max}, {min,max}):指定上面的元素允许重复的次数。
通配符 (.): 匹配任何字符。
字符类 […]: 表示一组可能的字符匹配。
备选方案 (|):隔开备用可能性。
单词边界 (\b):匹配单词类字符和非单词类字符或边缘之间的宽度界限。
(\s) 和 (\S) 匹配: 分别识别空格和非空格。
(\d) 和(\D) 匹配: 数字和非数字。
行首(^) 和行尾($) 匹配:自动识别行首和末尾。
这些行动为构建复杂模式提供了强有力的工具。
正则表达式历史
- 文本搜索和操作
搜索文本文档中的特定模式或关键字。
用所需格式取代文本(例如日期格式、电子邮件地址提取)。 - 数据验证和提取方式
验证用户输入(例如电子邮件验证、密码强度检查)。
从结构化文本中提取数据(例如日志文件、CSV数据)。 - 网页端开发
在 web 应用程序中进行表单验证和输入数据清理。
URL 路由和参数提取. - 编程和脚本
模式匹配和以编程语言提取数据。
日志文件解析和分析。 - 数据科学和自然语言处理
NLP 任务中的文本标识化和文本预处理。
数据提取和转换。
一些应用程序示例(在 Trados Studio中):
指定 HTML 标签元素
正则表达式: <(\/?)([a-zA-Z]+)([^>]*?)>
使用案例:确保内容中的 XML/HTML 标签的一致性,特别是对于网站本地化。
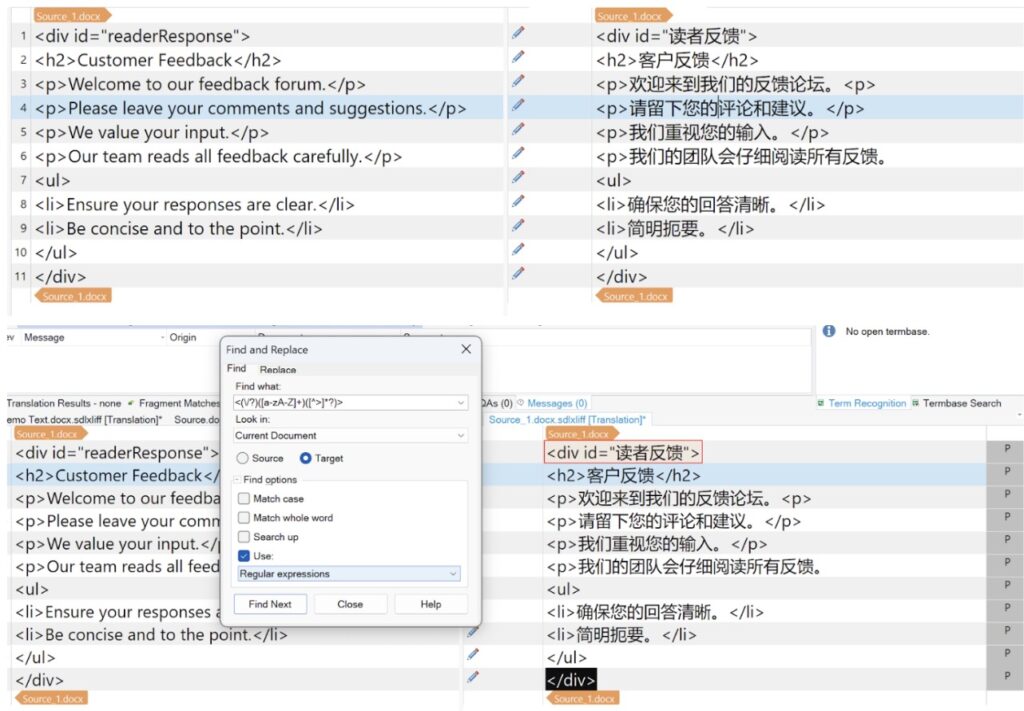
场景:假定语言学家在翻译界面中呈现原始的 HTML 元素,这种情况在Crowdin 这样的平台上并不罕见。 主要目标是确保这些HTML标签在翻译过程中保持不变。 然而,我们遇到了几个问题:在源文本中,语言学家错误地在第1行翻译了“div”标签的“id”属性。 第3行更改了标签,导致数据崩坏。 根据第6行,一个标签的结尾部分丢失。 这种设想强调了选择和突出所有标签元素的重要性,因为这将大大有助于质量保证管理员查明这种错误。 确保HTML标签的完整性对于本地化网站的顺利运作和防止它在最初启动时崩溃至关重要。
正在删除额外的白空间
在Trados中的应用
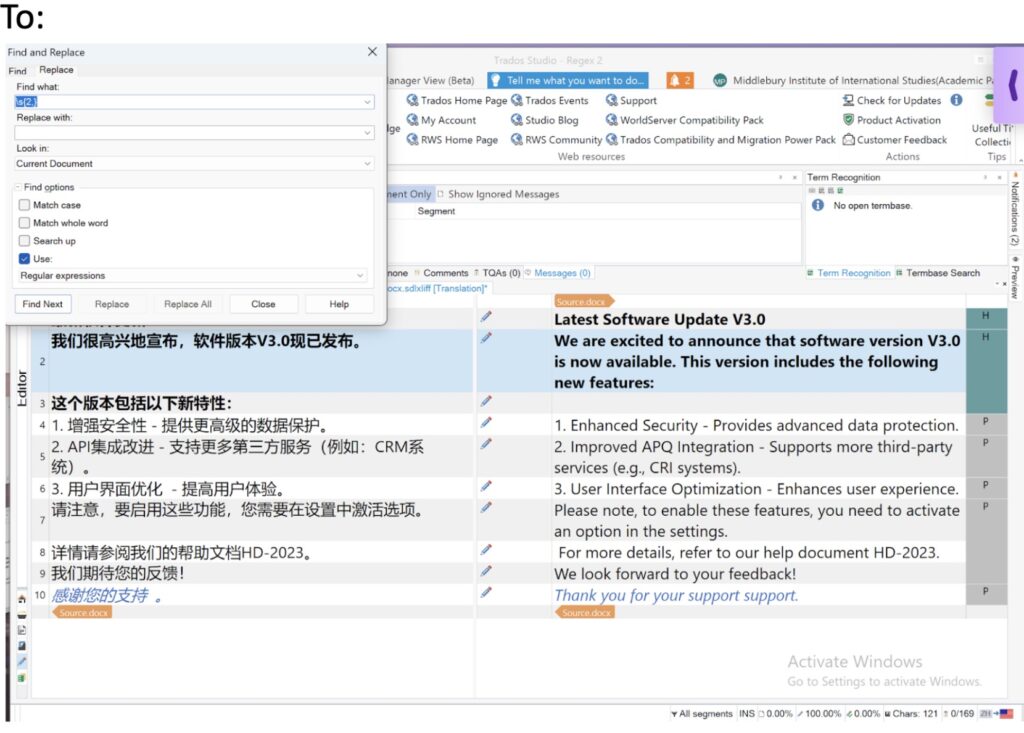
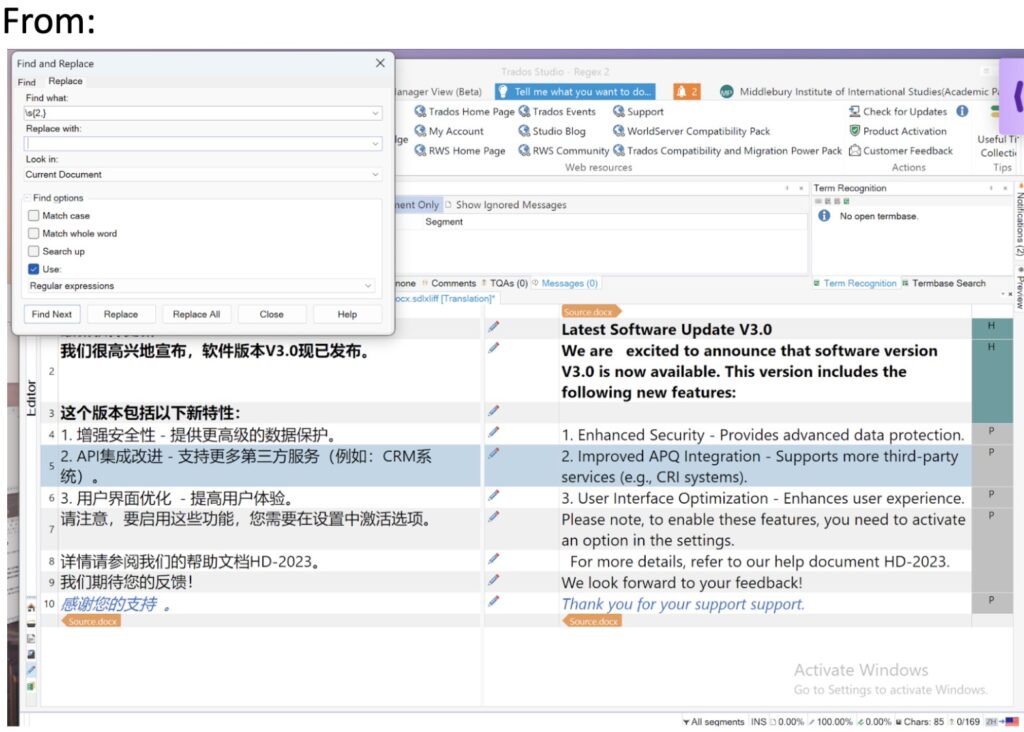
查找 \s{2,}
用单个空白替换。
\s 或一个简单的空格