Regular Expressions, commonly known as Regex or Regexp, are powerful tools for pattern matching and text manipulation. They have a rich history and find applications across various fields. In this tutorial, we'll explore the history, categories, grammar, and practical applications of Regular Expressions.History of Regular Expressions
1950s: The concept of regular expressions was first formalized by mathematician Stephen Cole Kleene. He used regular expressions to describe the syntax of formal languages.
1960s: Ken Thompson, the creator of Unix, implemented regular expressions in the QED text editor. This marked the introduction of regex into the world of computing.
1980s: Henry Spencer developed one of the first regex libraries, widely used in Unix systems.
1990s: Perl, a popular programming language, integrated regex as a core feature, making it accessible to a broader audience.
2000s: Regex support expanded to numerous programming languages, including Python, JavaScript, and Ruby.
Grammar of Regular Expressions
Elements
Literal Characters: Any character not listed as a metacharacter matches itself (e.g., ‘a’ matches ‘a’).
Metacharacters: Special characters with reserved meanings (e.g., ‘.’ matches any character).
Character Classes: Define sets of characters (e.g., ‘[aeiou]’ matches any vowel).
Quantifiers: Indicate the number of times a character or group should be repeated (e.g., ‘*’ matches zero or more times).
Anchors: Specify positions within the text (e.g., ‘^’ matches the start of a line).
Groups and Alternation: Use parentheses to group expressions and ‘|’ to denote alternatives (e.g., ‘(cat|dog)’ matches ‘cat’ or ‘dog’).
For a comprehensive understanding of regex grammar and operations, you can refer to the Wikipedia page on Regular Expressions.
Common Regex Operations
Boolean “or” (|): Separates alternatives. For example, gray|grey can match “gray” or “grey.”
Grouping (()): Groups a series of pattern elements to a single element. Allows referencing matched patterns using variables (e.g., $1, $2).
Quantification (?, *, +, {M}, {M,}, {,max}, {min,max}): Specifies how many times the preceding element is allowed to repeat.
Wildcard (.): Matches any character.
Character Classes ([…]): Denotes a set of possible character matches.
Alternation (|): Separates alternate possibilities.
Word Boundary (\b): Matches a zero-width boundary between a word-class character and either a non-word class character or an edge.
Whitespace (\s) and Non-Whitespace (\S) Matches: For spaces and non-spaces.
Digit (\d) and Non-Digit (\D) Matches: For digits and non-digits.
Line Begin (^) and Line End ($) Matches: For the beginning and end of a line or string.
These operations provide powerful tools for constructing complex patterns.
Applications of Regular Expressions
- Text Search and Manipulation
Searching for specific patterns or keywords in text documents.
Replacing text with desired formats (e.g., date formatting, email address extraction). - Data Validation and Extraction
Validating user input (e.g., email validation, password strength checks).
Extracting data from structured text (e.g., log files, CSV data). - Web Development
Form validation and input sanitization in web applications.
URL routing and parameter extraction. - Programming and Scripting
Pattern matching and data extraction in programming languages.
Log file parsing and analysis. - Data Science and Natural Language Processing
Tokenization and text preprocessing in NLP tasks.
Data extraction and transformation in data pipelines.
Some Application Examples (in Trados Studio):
Identify HTML tag elements
Regex: <(\/?)([a-zA-Z]+)([^>]*?)>
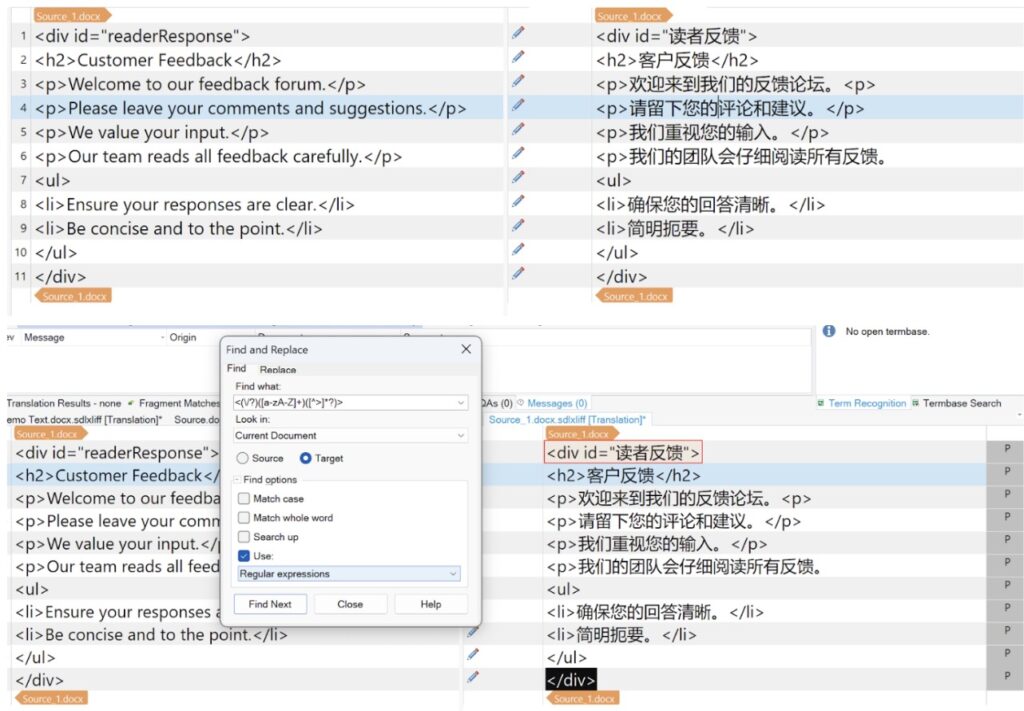
Use Case: Ensure consistency in XML/HTML tags within the content, especially for website localization.
Scenario: Suppose linguists are presented with raw HTML elements in their translation interface, a situation that is not uncommon in platforms like Crowdin. The primary objective is to ensure that these HTML tags remain unchanged during translation. However, we encounter several issues: In the source text, the linguist has mistakenly translated the ‘id’ attribute of a ‘div’ tag on line 1. On line 3, the tag is altered, leading to corruption. By line 6, the closing part of a tag is missing. This scenario underscores the importance of selecting and highlighting all tag elements, which can significantly aid a Quality Assurance Manager in identifying such errors. Ensuring the integrity of HTML tags is crucial for the smooth functioning of a localized website and to prevent it from crashing upon initial launch.
Removing Extra Whitespaces
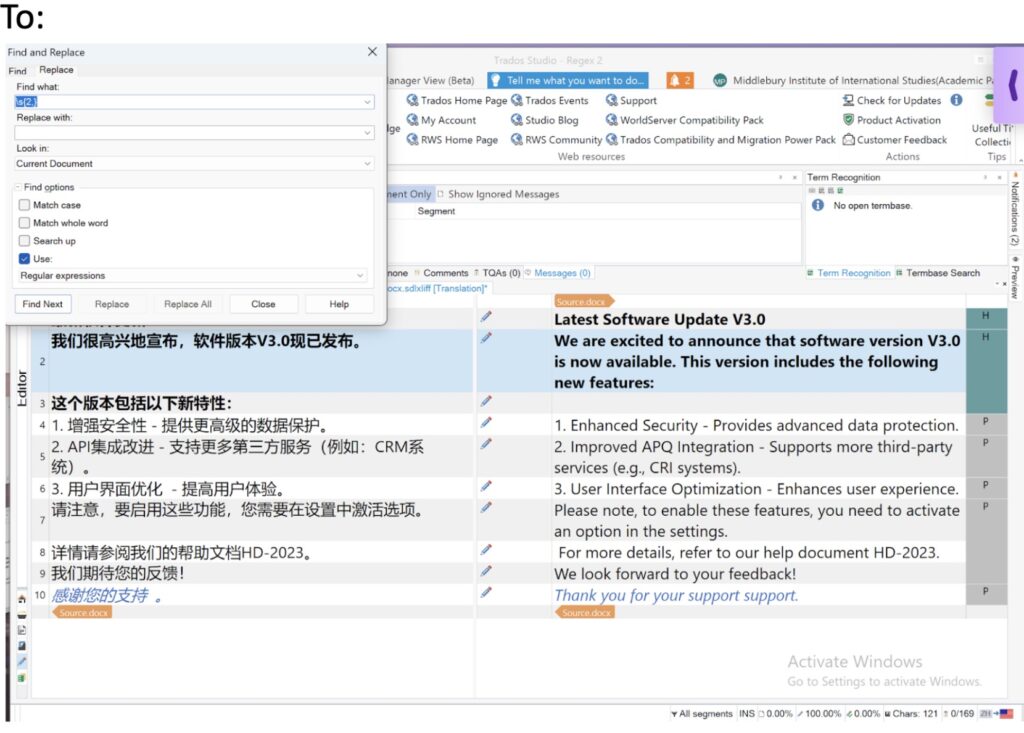
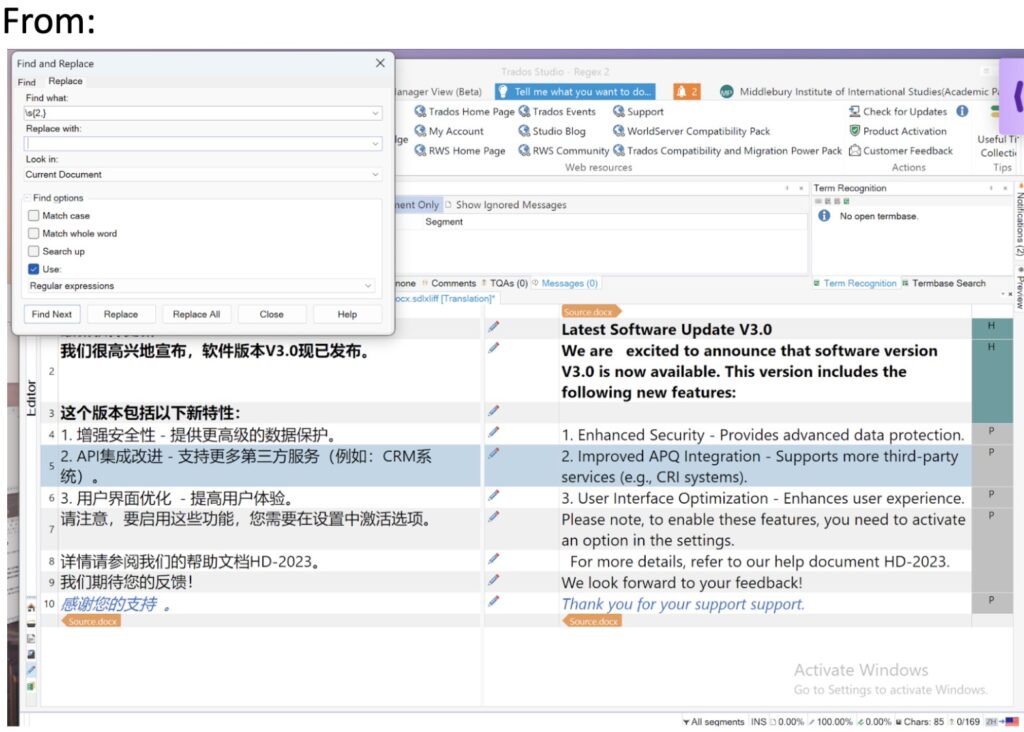
In Trados
Find \s{2,}
Replace with a single whitespace.
\s or a simple whitespace